Standaarddeviatie: wat is het en waarvoor dient het?

Statistieken worden gebruikt om de gegevens van een fenomeen te systematiseren, te verzamelen en te ordenen. Zo kun je de wetten afleiden en voorspellingen doen, beslissingen nemen en conclusies trekken. De werking ervan en de statistieken, zoals de standaarddeviatie, stellen ons in staat om getallen om te zetten in conclusies.
Hiermee kunnen we bijvoorbeeld de variabelen van een populatie beschrijven of conclusies trekken door het foutenniveau te beheersen.
Binnen statistieken dienen spreidingsmaten – zoals de standaarddeviatie – in wezen twee doelen. Een referentie vormen om te praten over de heterogeniteit van een populatie of steekproef en om het foutenniveau vast te stellen bij het maken van gevolgtrekkingen op basis van een betrouwbaarheidsniveau.
Voordat we dieper ingaan op de betekenis van de standaarddeviatie, gaan we eerst andere bijbehorende statistieken beschrijven die ook veel worden gebruikt in data-analyse.
Het gemiddelde en de variantie
Aan de ene kant is het gemiddelde een maatstaf voor de centrale tendens. Deze pretendeert een representatie te zijn van een steekproef of populatie in een variabele.
Bovendien heeft het een gevoel van wiskundige hoop, omdat we op de een of andere manier hopen dat, door willekeurig iemand te kiezen uit de populatie waarvan de steekproef deel uitmaakt, ze die waarde in die variabele zullen hebben.
Aan de andere kant is variantie een spreidingsmaat die de oscillatie van sommige gegevens in verhouding tot het gemiddelde ervan weergeeft. Het wordt berekend als de som van de residuen -verschil tussen waarde en gemiddelde – in het kwadraat gedeeld door het totaal van waarnemingen.
Laten we een voorbeeld nemen om het beter te begrijpen. Hieronder zie je een tabel waarin het aantal geproduceerde glazen door Johan, een glasblazer, te zien zijn.
Voorbeeld
| Doordeweekse dagen | Aantal geproduceerde glazen |
| maandag | 5 |
| Dinsdag | 4 |
| woensdag | 7 |
| donderdag | 3 |
| vrijdag | 6 |
Om het gemiddelde te berekenen tellen we het aantal geproduceerde glazen per dag op:
5 + 4 + 7 + 3 + 6 = 25
Vervolgens delen we het resultaat door het totale aantal gegevens:
25/5 = 5
Het gemiddelde aantal glazen dat Johan gedurende de vijf dagen heeft gemaakt, is vijf.
Om de variantie te vinden, is het noodzakelijk om de gekwadrateerde getallen te berekenen en deze te delen door het totale aantal waarnemingen.
In eenvoudiger bewoordingen trekken we het gemiddelde (5) af van de waarnemingen, het aantal kopjes dat per dag wordt gemaakt (5, 4, 7, 3 en 6) en kwadrateren het. Dan tellen we op en delen we door het aantal waarnemingen (5):
s² = (5-5) ² + (4-5) ² + (7-5) ² + (3-5) ² + (6-5) ² / 5 = 2
De variatie in het aantal geproduceerde glazen van de ene op de andere dag, in verhouding tot het gemiddelde, is twee. Deze gegevens, zo gezegd, zijn van weinig nut. We zouden de verkregen variantie echter kunnen vergelijken met die van andere weken. We zouden dan een idee krijgen van in welke weken Jorge constanter is geweest in de productie van glazen.
Standaardafwijking
De standaarddeviatie is een statistische maatstaf die ons informatie geeft over de gemiddelde spreiding van een variabele (López, 2017). Het is het gemiddelde van de individuele afwijkingen van elke waarneming van het gemiddelde van een verdeling. Deze afwijking is altijd groter dan of gelijk aan nul.
Een standaarddeviatie van 0, naar ons voorbeeld, zou optreden als Johan elke dag van de week een aantal glazen had geproduceerd die samenvielen met het gemiddelde.
Dit is een zeer zeldzaam geval, omdat het bijvoorbeeld zeer zeldzaam is dat alle mensen in een groep hetzelfde meten, hetzelfde wegen of hetzelfde prefereren. Dat wil zeggen, wat we verwachten is variabiliteit bij het analyseren van de gegevens van één variabele.
Hoe bereken je de standaarddeviatie?
Zodra we de waarde van het gemiddelde en de variantie van onze gegevens hebben gevonden, kunnen we de standaarddeviatie berekenen door de vierkantswortel van de laatste te nemen. Laten we dit in de praktijk brengen door de standaarddeviatie te vinden van het aantal glazen dat Johan in vijf dagen heeft gemaakt:
S = √ (5-5) ² + (4-5) ² + (7-5) ² + (3-5) ² + (6-5) ² / 5 = 1,41
Dit voorbeeld illustreert hoe we door deze spreidingsmaatstaf gemiddeld kunnen weten hoe een populatie eruitziet met betrekking tot een variabele (min of meer heterogeen).
De media praat vaak alleen over middelen. Daarom kennen we een waarde toe aan een populatie in een variabele, wanneer er grote heterogeniteit kan zijn. Zozeer zelfs dat deze gemiddelde waarde eigenlijk niemand in de populatie echt vertegenwoordigt.
Het zou bijvoorbeeld zo kunnen zijn dat Johan op geen enkele dag vijf glazen produceerde. De kop zou echter kunnen zijn: “Johan maakt vijf glazen per dag.” Paradoxaal, toch?
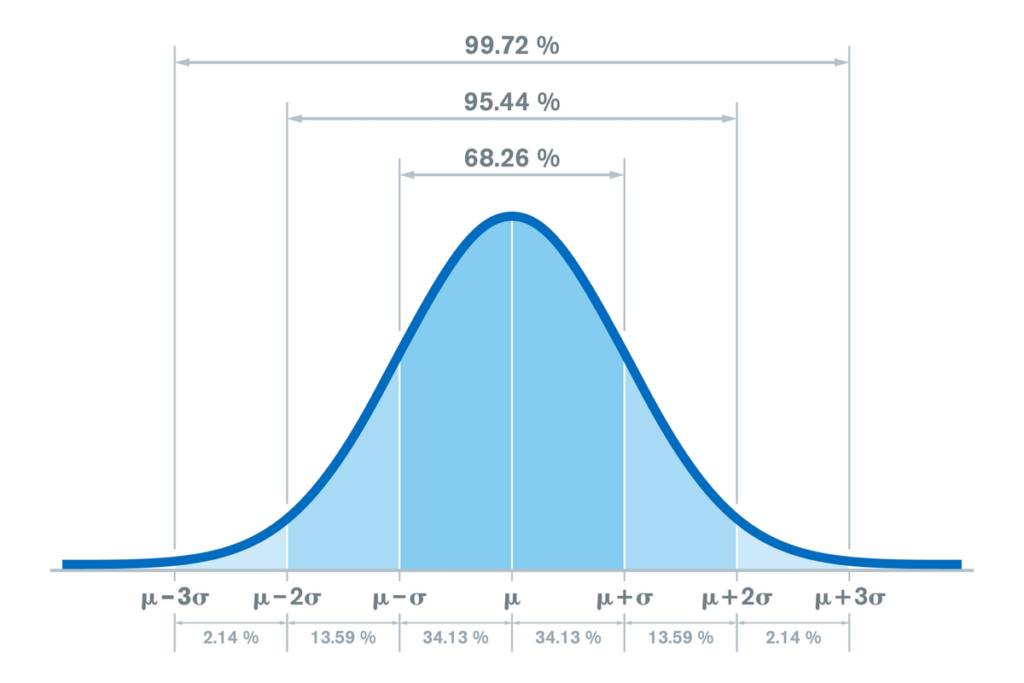
Waar is de standaarddeviatie voor?
Men gebruikt bijvoorbeeld het om te schatten hoe verspreid de gegevens zijn ten opzichte van het gemiddelde van de variabele die wordt bestudeerd. Ze stellen ons in staat om gemiddeld te weten hoe de waarnemingen rond het gemiddelde zijn geconcentreerd.
De standaarddeviatie is dus een index die moet worden gebruikt bij het beschrijven van de variabiliteit van een continue variabele in een steekproef (Abraira, 2002).
Naast het dienen als referentie om de variabiliteit van een populatie te analyseren, dient het ook om de breedte van het betrouwbaarheidsinterval in te stellen bij het maken van gevolgtrekkingen over het gemiddelde.
Hoe groter de standaarddeviatie, hoe groter de interval. Daardoor is het bijvoorbeeld moeilijker om van significante verschillen tussen twee populaties te spreken.
Op psychometrisch niveau zou het te maken hebben met betrouwbaarheid, wat in sommige gevallen kan worden opgevat als de stabiliteit van de resultaten die in de tijd zijn verkregen in longitudinale onderzoeken. Een test zou dus betrouwbaar zijn wanneer deze zeer vergelijkbare metingen oplevert voor dezelfde reële waarde.
Alle siterte kilder ble grundig gjennomgått av teamet vårt for å sikre deres kvalitet, pålitelighet, aktualitet og validitet. Bibliografien i denne artikkelen ble betraktet som pålitelig og av akademisk eller vitenskapelig nøyaktighet.
- Abraira, V. (2002). Desviación estándar y error estándar. SEMERGEN-Medicina de Familia, 28(11), 621-623. https://www.elsevier.es/es-revista-medicina-familia-semergen-40-articulo-desviacion-estandar-error-estandar-S1138359302741385
- Hurley, M., & Tenny, S. (2022). Mean. StatPearls. Consultado el 28 de julio de 2023. https://www.ncbi.nlm.nih.gov/books/NBK546702/ https://www.ncbi.nlm.nih.gov/books/NBK546702/
- National Library of Medicine. (s.f.). Standard Deviation. Consultado el 28 de julio de 2023. https://www.nlm.nih.gov/nichsr/stats_tutorial/section2/mod8_sd.html#:~:text=A%20standard%20deviation%20(or%20%CF%83,data%20are%20more%20spread%20out.
- López, J.F. (02 de octubre, 2017). Desviación estándar o típica. Economipedia. Consultado el 13 de octubre de 2021. https://economipedia.com/definiciones/desviacion-tipica.html
- Salazar, C. y Del Castillo, S. (2017). Fundamentos básicos de estadística. Sin editorial.
- The BMJ. (s.f.). Mean and standard deviation. Consultado el 13 de octubre de 2021. https://www.bmj.com/about-bmj/resources-readers/publications/statistics-square-one/2-mean-and-standard-deviation
- Wadhwa, R. R., & Azzam, D. (2019). Variance. StatPearls. Consultado el 28 de julio de 2023. https://www.ncbi.nlm.nih.gov/books/NBK551689/#:~:text=Although%20the%20arithmetic%20mean%20of,spread%20around%20its%20center.%5B2







